Home
![]()
TAXonomic Profile Aggregation and STAndardisation
About¶
The main purpose of taxpasta is to standardise taxonomic profiles created by a range of bioinformatics tools. We call those tools taxonomic profilers. They each come with their own particular tabular output format. Across the profilers, relative abundances can be reported in read counts, fractions, or percentages, as well as any number of additional columns with extra information. We therefore decided to take the lessons learnt to heart and provide our own solution to deal with this pasticcio. With taxpasta you can ingest all of those formats and, at a minimum, output taxonomy identifiers and their integer counts. Taxpasta can not only standardise profiles but also merge them across samples for the same profiler into a single table.
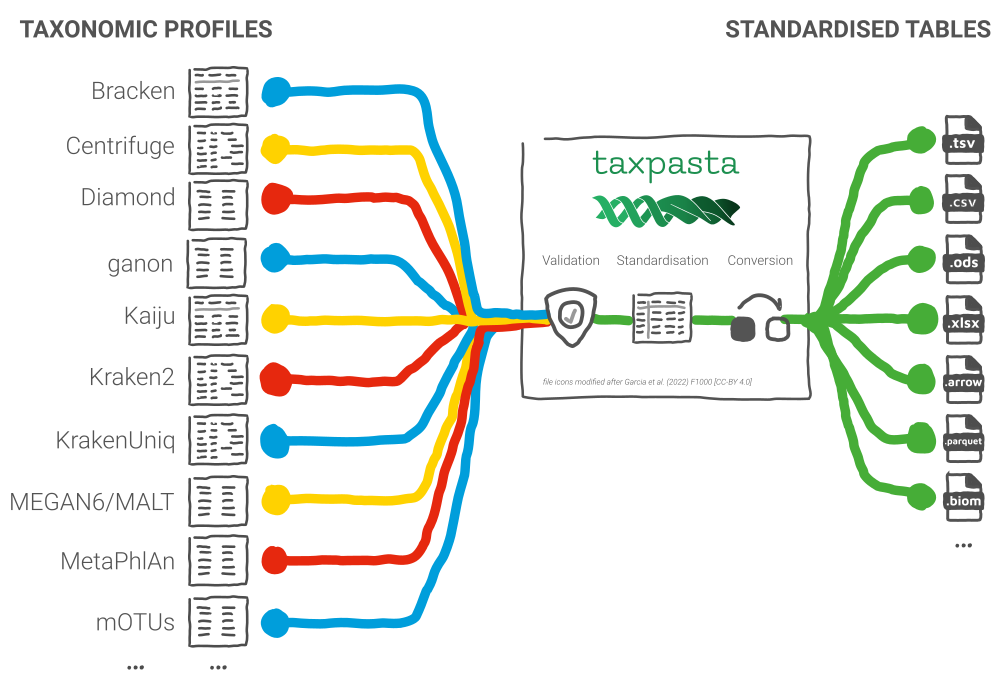
Supported Taxonomic Profilers¶
Taxpasta currently supports standardisation and generation of comparable taxonomic tables for:
See supported profilers for more information.
Install¶
It's as simple as:
Taxpasta is also available from the Bioconda channel
and thus automatically generated Docker and Singularity BioContainers images also exist.
Optional Dependencies¶
Taxpasta supports a number of extras that you can install for additional features; primarily support for additional output file formats. You can install them by specifying a comma separated list within square brackets, for example,
richprovides rich-formatted command line output and logging.arrowsupports writing output tables in Apache Arrow format.parquetsupports writing output tables in Apache Parquet format.biomsupports writing output tables in BIOM format.odssupports writing output tables in ODS format.xlsxsupports writing output tables in Microsoft Excel format.allincludes all of the above.devprovides all tools needed for contributing to taxpasta.
Usage¶
The main entry point for taxpasta is its command-line interface (CLI). You can interactively explore the offered commands through the help system.
See the Getting Started tutorial to get familiar with Taxpasta.
Taxpasta currently offers two commands corresponding to the main use-cases. You can find out more in the commands' documentation.
Standardise¶
Since the supported profilers all produce their own flavour of tabular output, a quick way to normalize such files, is to standardise them with taxpasta. You need to let taxpasta know what tool the file was created by. As an example, let's standardise a MetaPhlAn profile. (You can find an example file in our test data.)
curl -O https://raw.githubusercontent.com/taxprofiler/taxpasta/main/tests/data/metaphlan/MOCK_002_Illumina_Hiseq_3000_se_metaphlan3-db.metaphlan3_profile.txt
taxpasta standardise -p metaphlan -o standardised.tsv MOCK_002_Illumina_Hiseq_3000_se_metaphlan3-db.metaphlan3_profile.txt
With these minimal arguments, taxpasta produces a two column output consisting of
| taxonomy_id | count |
|---|---|
You can count on the second column being integers  Having such a simple
and tidy table should make your downstream analysis much smoother to start out
with. Please, have a look at the full getting
started tutorial for a more thorough
introduction.
Having such a simple
and tidy table should make your downstream analysis much smoother to start out
with. Please, have a look at the full getting
started tutorial for a more thorough
introduction.
Merge¶
Converting single tables is nice, but hopefully you have many shiny samples to
analyze. The taxpasta merge command works similarly to standardise except
that you provide multiple profiles as input. Grab a few more MOCK examples from
our test
data and
try it out.
LOCATION=https://raw.githubusercontent.com/taxprofiler/taxpasta/main/tests/data/metaphlan
curl -O "${LOCATION}/MOCK_001_Illumina_Hiseq_3000_se_metaphlan3-db.metaphlan3_profile.txt"
curl -O "${LOCATION}/MOCK_002_Illumina_Hiseq_3000_se_metaphlan3-db.metaphlan3_profile.txt"
curl -O "${LOCATION}/MOCK_003_Illumina_Hiseq_3000_se_metaphlan3-db.metaphlan3_profile.txt"
taxpasta merge -p metaphlan -o merged.tsv MOCK_*.metaphlan3_profile.txt
The output of the merge command has one column for the taxonomy identifier and
one more column for each input profile. Again, please have a look at the full
getting started tutorial for a more thorough
introduction.
Citation¶
If you use TAXPASTA in your academic work, please cite our article in the Journal of Open Source Software.
Beber, M. E., Borry, M., Stamouli, S., & Fellows Yates, J. A. (2023). TAXPASTA: TAXonomic Profile Aggregation and STAndardisation. Journal of Open Source Software, 8(87), 5627. https://doi.org/10.21105/joss.05627
Acknowledgments¶
Many thanks to:
- nf-core for bringing together the original developers
- Zandra Fagernäs for the logo design
Copyright¶
- Copyright © 2022-2024, Moritz E. Beber, Maxime Borry, James A. Fellows Yates, and Sofia Stamouli.
- Free software distributed under the Apache Software License 2.0.